데이터베이스
[코멘토] SQL 입문부터 활용까지 - 데이터 분석 보고서 작성과 대시보드 개발 2차 과제
- -
실전 데이터 추출 업무를 수행한다.
Northwind Database를 활용한 문제 해결 (Redash)
- 모든 문제는 하나의 쿼리로 해결 가능합니다.
( 단, 하나의 쿼리로 정리하기 어려운 경우는 여러 개의 쿼리로 나눠서 문제를 푸시고, 그 과정을 적어주세요.)
Northwind Database는 다음과 같은 구조를 가지고 있다.
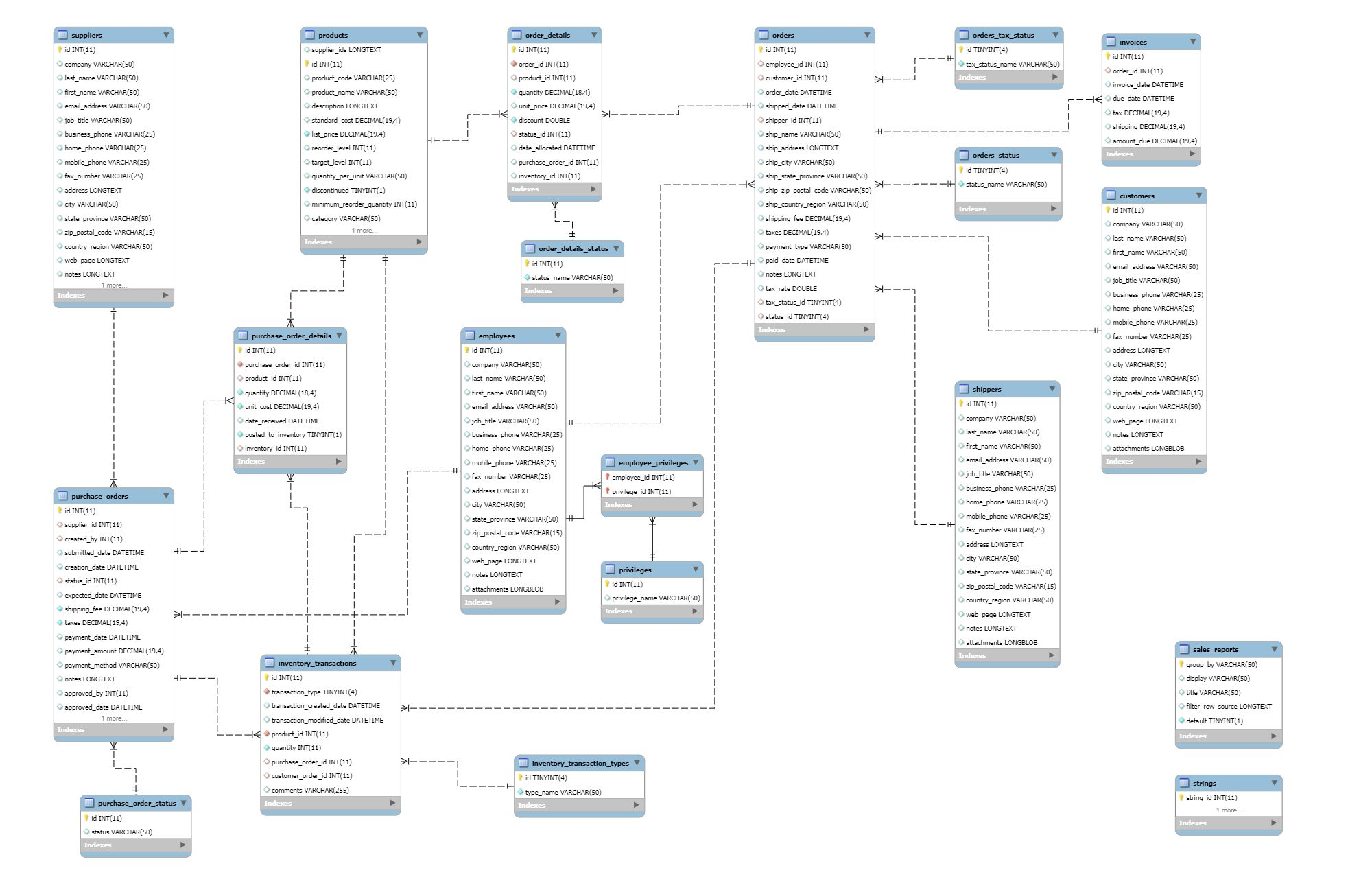

1. 상품(product)의 카테고리(category)별로, 상품 수와 평균 가격대(list_price)를 찾는 쿼리를 작성하세요.
[내 답변]
SELECT category, count(product_code) AS "상품 수", avg(list_price) AS "평균 가격대"
FROM products
GROUP BY category;저번 과제에서 count() 안에 칼럼명을 넣지 않고 count(1)과 같이 쓰는 게 낫다고 피드백을 주셨는데, 이해를 못해서 질문하였었다. 피드백 및 답변 내용은 아래와 같다.
[결과 화면]

- 멘토님 피드백 : count()에 대해서는 다음과 같은 사항을 참고로 알아두시기 바랍니다.
count() 안에 컬럼명을 넣으면 그 컬럼 값이 null이 있을 때는 카운트를 하지 않고, null이 아닌 경우에만 카운트를 하겠다는 의미입니다. 반면 count(1)과 같이 컬럼명이 없으면 null이 있어도 카운트를 하게 되고, 그냥 row수를 세는 것과 같은 의미입니다. 일반적으로는 일부 컬럼에 null 값이 있어도 전체적인 row 수를 파악하는 것이 더 중요한 경우가 많아 count(1)을 사용하는 경우가 더 많은 것 같습니다. 참고로 count(1)과 count(*)에는 차이가 없다고 보셔도 무방합니다.
[예시 답안]
select category, count(1) cnt, avg(list_price) avg_price
from products
group by category;[결과 화면]

2. 2006년 1분기에 고객(customer)별 주문(order) 횟수, 주문한 상품(product)의 카테고리(category) 수, 총 주문 금액(quantity * unit_price)을 찾는 쿼리를 작성하세요. (힌트: join)
[내 답변]
SELECT o.customer_id AS "고객ID", count(distinct o.id) AS "주문 횟수",
count(distinct p.category) AS "카테고리 수",
sum(od.quantity * od.unit_price) "총 주문 금액"
FROM orders o, order_details od, products p
WHERE o.id = od.order_id
AND p.id = od.product_id
AND '2006-01-01' <= o.order_date
AND o.order_date < '2006-04-01'
GROUP BY o.customer_id;[결과 화면]

- 멘토님 피드백 : 2주차에 학습한 내용을 토대로 Northwind DB에 대한 ERD를 확인해보시면 orders 테이블과 order_details 테이블은 1:N 관계에 있습니다. 즉 order_details 테이블에는 한 id에 여러 order_id가 존재할 수 있다는 의미입니다. 이 문제에서 처럼 주문 횟수를 세기 위해서는 결국 order_id를 세면 되는 것인데, 바로 이 order_id가 중복이 될 수 있기 때문에 그냥 count()를 하면 안됩니다. 이때 사용할 수 있는 문법이 바로 count(distinct 컬럼명) 입니다. 마찬가지 이유로 category 수를 세기 위해서도 distinct가 필요합니다. Good!
[예시 답안]
select o.customer_id,
count(distinct o.id) order_cnt,
count(distinct p.category) category_cnt,
sum(od.quantity * od.unit_price) sum_of_order_price
from orders o
left join order_details od on o.id = od.order_id
left join products p on od.product_id = p.id
where '2006-01-01' <= o.order_date
and o.order_date < '2006-04-01'
group by o.customer_id;[실행 결과]

3. 2006년 3월에 주문(order)된 건의 주문 상태(status_name)를 찾는 쿼리를 작성하세요. (join을 사용하지 않고 쿼리를 작성하세요.) (힌트: sub-query)
[내 답변]
이는 스칼라 부속질의를 이용하여 쿼리를 작성할 수 있다.
- 스칼라 부속질의 : SELECT문 안에 SQL문을 하나 더 작성하는 것
SELECT id "주문 ID", status_id AS "상태 번호", (SELECT status_name FROM orders_status os WHERE o.status_id = os.id) "주문 상태"
FROM orders o
WHERE '2006-03-01' <= order_date AND order_date < '2006-04-01';[실행 결과]

- 멘토님 피드백 : orders 테이블에는 status_id라고 해서 의미를 알 수 없는 숫자만 적어놓고, 이 숫자의 의미를 알기 위해서는 orders_status 테이블을 봐야 합니다. 이런 식으로 테이블을 구성하는 걸 ‘코드화’한다고 합니다. 즉 status_id는 코드이고, 코드 값은 status_name 입니다. 그냥 간단하게 orders 테이블에 문자열로 주문상태를 기록해두면 좋을 텐데 굳이 이렇게 코드화를 하는 이유는 저장공간을 아끼기 위해서 입니다. 컬럼 한 두 개야 크게 차이는 없겠지만 이런 컬럼이 많아지고, 그런 테이블이 많아지고 하다보면 전체적으로는 큰 차이가 생길 수 있어 보통 이런 코드화를 많이 합니다. 이 문제는 바로 이런 코드화 되어있는 값을 읽어오는 경우에 대한 예제라고 생각하시면 됩니다.
사실 join을 이용하면 훨씬 쉽게 짤 수도 있는 쿼리인데, 이런 식으로 select 절에 subquery를 쓰는 방법도 있습니다. 특히 이 문제와 같이 코드 값을 읽어오는 경우에 이렇게 subquery를 사용하는 걸 약간의 테크닉처럼 많이 사용하는 것 같습니다. Join을 이용한 방법도 전혀 문제는 없지만 자주 나오는 패턴이라 같이 익혀두시면 좋을 것 같습니다. Join을 이용한 쿼리는 예시답안을 참고해주세요.
참고로 subquery는 전혀 어렵게 생각하실 필요가 없습니다. 그저 쿼리안에 또 다른 쿼리가 나오는 형태일 뿐이고, 쿼리를 작성하는 도중에 ‘아 이 부분에는 다른 쿼리로 미리 계산된 결과를 사용하고 싶다’라는 생각이 들 때 활용해 볼 만한 문법입니다. 쿼리를 읽으실 때도 도중에 subquery를 만나면 잠시 그 쿼리 안으로 들어가서 내용을 해석하고 다시 밖으로 나오면 됩니다. 혹시라도 인터넷에서 자료를 찾아보시다가 subquery가 쿼리 안 어디에 위치하는 지에 따라서 이름을 다르게 부르는 것은 굳이 알아두실 필요가 없습니다(select 절에 나오면 뭐고, from 절에 나오면 뭐고 하는 식으로). 현업에서는 전혀 사용하지 않는 용어입니다. subquery는 쿼리 어디에서든지 나올 수 있고, 그저 쿼리안의 쿼리일 뿐입니다.
[예시 답안]
(3-1) subquery 를 사용했을 때
select id, status_id, (select status_name from orders_status os where os.id = o.status_id) status_name
from orders o
where '2006-03-01' <= order_date
and order_date < '2006-04-01';(3-2) join을 사용했을 때
select o.id, os.id, os.status_name
from orders o
left join orders_status os on o.status_id = os.id
where '2006-03-01' <= o.order_date
and o.order_date < '2006-04-01';[실행 결과]

4. 2006년 1분기 동안 세 번 이상 주문(order) 된 상품(product)과 그 상품의 주문 수를 찾는 쿼리를 작성하세요. (order_status는 신경쓰지 않으셔도 됩니다.) (힌트: sub-query or having)
[내 답변]
SELECT od.product_id AS "상품ID", count(od.order_id) AS "주문 수"
FROM order_details od
JOIN orders o ON od.order_id = o.id
WHERE o.order_date between '20060101' AND '20060331'
GROUP BY od.product_id
HAVING count(o.id) >= 3;[실행 결과]

- 멘토님 피드백 : having 을 사용하는 것이 핵심인 문제였는데 잘 해결하셨습니다.
다만, 이 경우에도 count()에는 distinct가 들어가는 것이 더 정확합니다.
[예시 답안]
(1) subquery를 사용했을 때
select *
from (
select product_id, count(distinct o.id) cnt
from orders o
left join order_details od on o.id = od.order_id
where '2006-01-01' <= order_date
and order_date < '2006-04-01'
group by product_id
) a
where cnt >= 3(2) having을 사용했을 때
select product_id, count(distinct o.id) cnt
from orders o
left join order_details od on o.id = od.order_id
where '2006-01-01' <= order_date
and order_date < '2006-04-01'
group by product_id
having count(distinct o.id) >= 3;
5-1. 2006년 1분기, 2분기 연속으로 하나 이상의 주문(order)을 받은 직원(employee)을 찾는 쿼리를 작성하세요. (order_status는 신경쓰지 않으셔도 됩니다.) (힌트: sub-query, inner join)
-- 1분기: 1,3,4,6,8,9
-- 2분기: 1,2,3,4,6,7,8,9
[내 답변] - 틀림.
select distinct employee_id
from orders
where ('2006-01-01' <= order_date
and order_date < '2006-04-01') and ('2006-04-01' <= order_date
OR order_date < '2006-07-01');[실행 결과]

- 멘토님 피드백 : Inner join을 통해 교집합을 구현하는 것이 핵심인 문제였습니다. 1분기에 주문을 받은 직원과 2분기에 주문을 받은 직원을 subquery를 통해 각각 따로 만든 다음 inner join을 통해 그 둘의 교집합을 계산하면 됩니다.
where 절에 and로 분기별 조건을 연결하게 되면 1분기 이면서 동시에 2분기인 날짜를 골라내는 조건을 거는 것과 같습니다. 그런 날짜가 실제로 없기 때문에 이렇게 쿼리를 작성하시면 결과가 나오지 않게 됩니다.
[예시 답안]
select o1.employee_id
from
(select distinct employee_id
from orders
where '2006-01-01' <= order_date
and order_date < '2006-04-01') o1
inner join
(select distinct employee_id
from orders
where '2006-04-01' <= order_date
and order_date < '2006-07-01') o2
on o1.employee_id = o2.employee_id;[실행 결과]

5-2. 2006년 1분기, 2분기 연속으로 하나 이상의 주문을 받은 직원별로, 월별 주문 수를 찾는 쿼리를 작성하세요. (order_status는 신경쓰지 않으셔도 됩니다.) (힌트: sub-query 중첩, date_format() )
[내 답변]
SELECT e.id AS "직원 ID",
date_format(o.order_date,'%Y-%m') AS "2006년 월별",
count(o.id) AS "주문 수"
FROM employees e
JOIN orders o ON e.id = o.employee_id
where e.id in
(SELECT employee_id
FROM orders
WHERE (order_date between '20060101' AND '20060331')
AND (order_date between '200600401' AND '20060630')
GROUP BY employee_id
HAVING count(orders.id) >= 1
)
GROUP BY e.id,
date_format(o.order_date,'%Y-%m' );[실행 결과]

- 멘토님 피드백 : 5-1에서 작성한 쿼리를 활용해 where 절에 서브쿼리로 그대로 넣어서 조건을 만족하는 특정 employee를 골라내고, 연월별로, 직원별로 집계를 하기 위해서 group by를 해주는 것이 핵심인 문제였습니다.
참고로 group by 1, 2는 select 절에 있는 첫 번째, 두 번째 컬럼으로 group by를 하겠다는 의미로 쿼리를 편하게 줄여서 쓴 것입니다. 이런 편의 기능도 사용해 보셔도 좋을 것 같습니다.
employee 정보는 orders에도 있기 때문에 굳이 join해오지 않으셔도 됩니다.
employees 테이블까지 join을 해 왔다면 count(distinct orders.id), orders 테이블만 있었다면 그냥 count(1)을 해주시면 되겠습니다.
[예시 답안]
select employee_id, date_format(order_date, '%Y-%m') ym, count(1) cnt
from orders
where employee_id in (
select o1.employee_id
from
(select distinct employee_id
from orders
where '2006-01-01' <= order_date
and order_date < '2006-04-01') o1
inner join
(select distinct employee_id
from orders
where '2006-04-01' <= order_date
and order_date < '2006-07-01') o2
on o1.employee_id = o2.employee_id
)
group by 1, 2;[실행 결과]

정리
1. count() 안에 컬럼명을 넣으면 그 컬럼 값이 null이 있을 때는 카운트를 하지 않고, null이 아닌 경우에만 카운트를 하겠다는 의미다. 반면 count(1)과 같이 컬럼명이 없으면 null이 있어도 카운트를 하게 되고, 그냥 row수를 세는 것과 같은 의미가 된다. 일반적으로는 일부 컬럼에 null 값이 있어도 전체적인 row 수를 파악하는 것이 더 중요한 경우가 많아 count(1)을 사용하는 경우가 더 많은 것 같다. 참고로 count(1)과 count(*)에는 차이가 없다고 보셔도 무방하다.
2. 만약 중복되는 값을 피해서 count를 하고 싶다면, count(distinct 칼럼명)을 해줘야 한다.
3. 코드화를 하는 이유는 저장공간을 아끼기 위해서다. subquery의 이름은 중요하지 않고, 쓰임이 중요하다.
4. group by 1, 2는 select 절에 있는 첫 번째, 두 번째 컬럼으로 group by를 하겠다는 의미로 쿼리를 편하게 줄여서 쓴 것이다.이런 편의 기능도 많이 사용해 보자.
'데이터베이스' 카테고리의 다른 글
| 데이터베이스 기말고사 내용정리 (0) | 2023.01.30 |
|---|---|
| [코멘토] SQL 입문부터 활용까지 - 데이터 분석 보고서 작성과 대시보드 개발 1차 과제 (2) | 2022.12.24 |
| 데이터베이스 중간고사 내용 정리 (2) | 2022.10.29 |
Contents
소중한 공감 감사합니다